近日,武汉大学遥感信息工程学院季顺平教授团队联合Skywork AI提出首个统一了“通用分割(语义分割、实例分割、全景分割等)、提示驱动的分割(通过点、框、涂鸦等视觉prompt引导兴趣目标的识别和分割)、指令调整(由语言或文本指令训练大模型的理解和推理能力)的多模态大模型OMG-LLaVA。相关论文[1]被NeurIPS2024接收,NeurIPS是机器学习和人工智能领域的国际顶级会议。第一作者是2023级博士研究生张韬。
人工智能的研究热点逐渐从以ChatGPT为代表的语言大模型(Large Language Model, LLM)过渡到更通用的多模态大模型(Large Multimodal Model, LMM),如OpenAI的Gpt-4v、谷歌的Gemini,以及开源的LLaVA。目前,虽然多模态大模型已经具备强大的图像级对话和推理能力,但尚缺乏像素级的精细理解能力。而像素级的图像理解和推理是计算机视觉、遥感等领域的核心内容。团队提出OMG-LLaVA,将像素级视觉理解与推理能力嵌入多模态大模型中,将进一步促进多模态大模型在计算机视觉和遥感中的深入应用。
OMG-LLaVA构建简洁的结构实现多任务的统一。它接受各种灵活的视觉和文本提示。特别地,采用通用分割方法作为视觉编码器,将图像信息、感知先验和视觉提示与文本对齐后提供给LLM。LLM理解用户指令,输出文本响应和像素级分割结果。
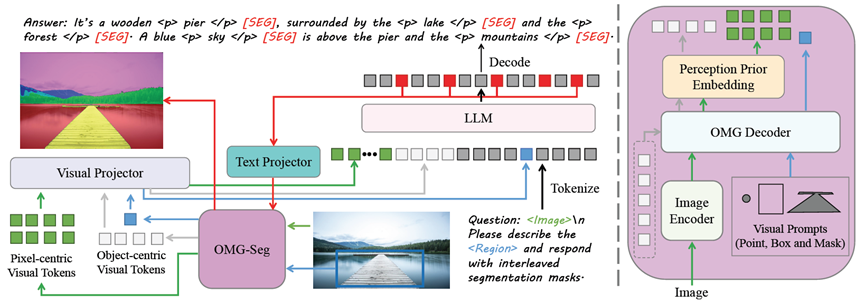
OMG-LLaVA架构
具体地,OMG-LLaVA统一了图像级——如图像内容概括和图像对话,目标级——如图像局部内容概括和基于视觉提示的对话,和像素级——包括语义分割、实例分割等通用分割,描述分割(referring segmentation,根据一段明确的描述去分割目标),推理分割(reasoning segmentation,通过更复杂的推理去理解和分割目标)以及像素级图像对话(grounded conversation generation)等一系列视觉理解和推理任务。为实现这种多层次通用能力,定义了三种令牌(tokens)类型:文本令牌、像素令牌、目标令牌,分别处理文字、密集图像特征、目标特征。然后,将各类不同的任务统一建模为令牌到令牌的生成(token-to-token generation)。最终,将令牌解码为特定任务所要求的语言文字、分割掩膜等等。在性能上,在大量数据集上的实验证实了更加通用的OMG-LLaVA能够匹配甚至超过专门的方法。

[描述分割(referring segmentation)]

[推理分割(reasoning segmentation)]

[像素级图像对话生成(grounded conversation generation)]
[1] arxiv.org/pdf/2406.19389.