近日,武汉大学遥感信息工程学院季顺平教授团队“通用视频分割”成果“DVIS++: Improved Decoupled Framework for Universal Video Segmentation”被计算机视觉顶级期刊IEEE Transactions on Pattern Analysis and Machine Intelligence(IF=20.8)录用。第一作者为2023届博士研究生张韬。DVIS++是DVIS(Decoupled VIdeo Segmentation)方法的扩展,实现了各类视频的语义分割、实例分割、全景分割。DVIS++具备开放词汇(open-vocabulary)能力,能实现未知目标的分割,命名为OV-DVIS++。DVIS是2023年提出的方法,曾获得国际顶级会议CVPR挑战赛“视频语义全景分割(Wild Challenge VPS Track)”和ICCV挑战赛“视频实例分割(VIS Track)”赛道双冠军。

除了遥感界熟悉的语义分割,实例分割和全景分割如下图所示。视频实例分割中,每只家禽用不同色彩掩膜代表不同实例。全景实例分割中,可数目标用实例分割,不可数目标(如天空)用语义分割。


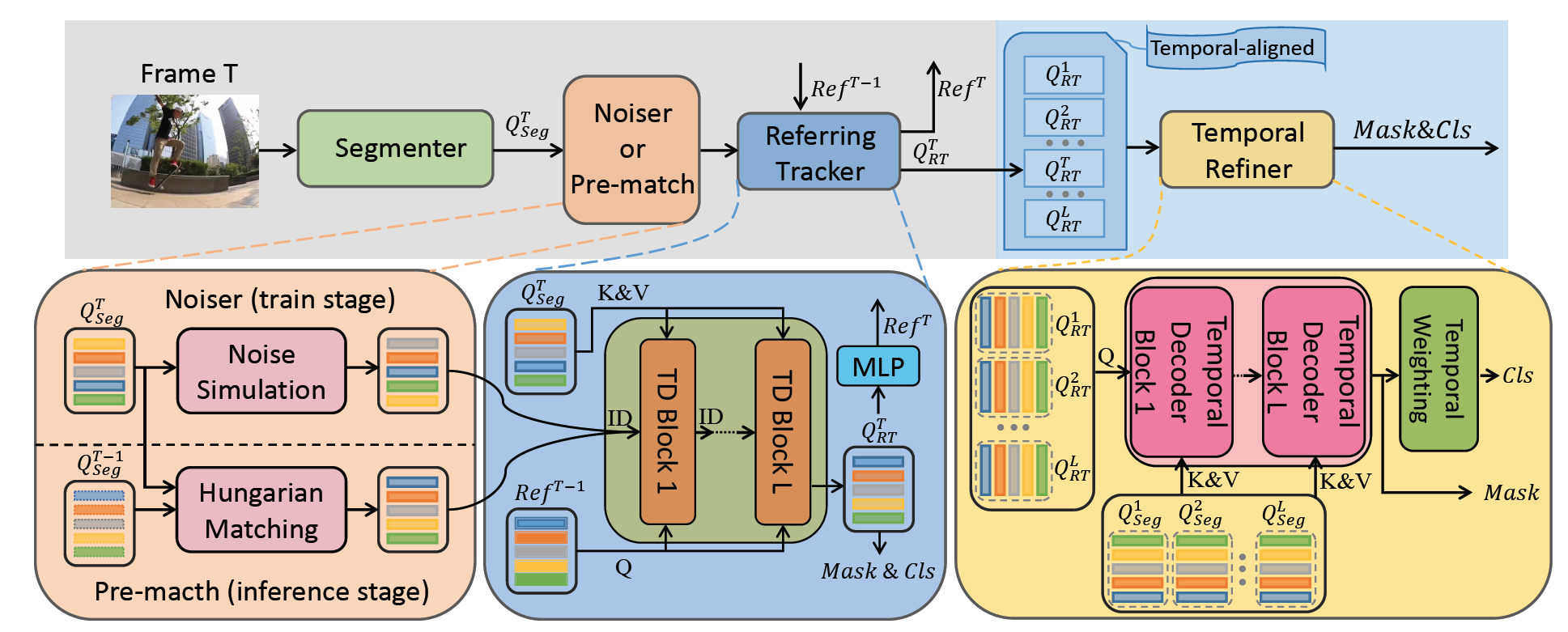
DVIS方法将视频分割解耦为三个级联子任务:分割、跟踪与优化。通过视觉基础模型提取每帧图像的高级特征;设计“参考追踪器”实现目标的逐帧追踪;设计“时序优化器”构建更长序列的时空表征。为进一步增强DVIS的追踪能力,论文提出去噪训练策略并引入对比学习,由此构建更鲁棒的DVIS++框架,如下图所示。去噪训练指在训练过程中加入遮挡等不利条件(通常开源训练数据是“干净的”),提升模型在干扰背景下的性能。
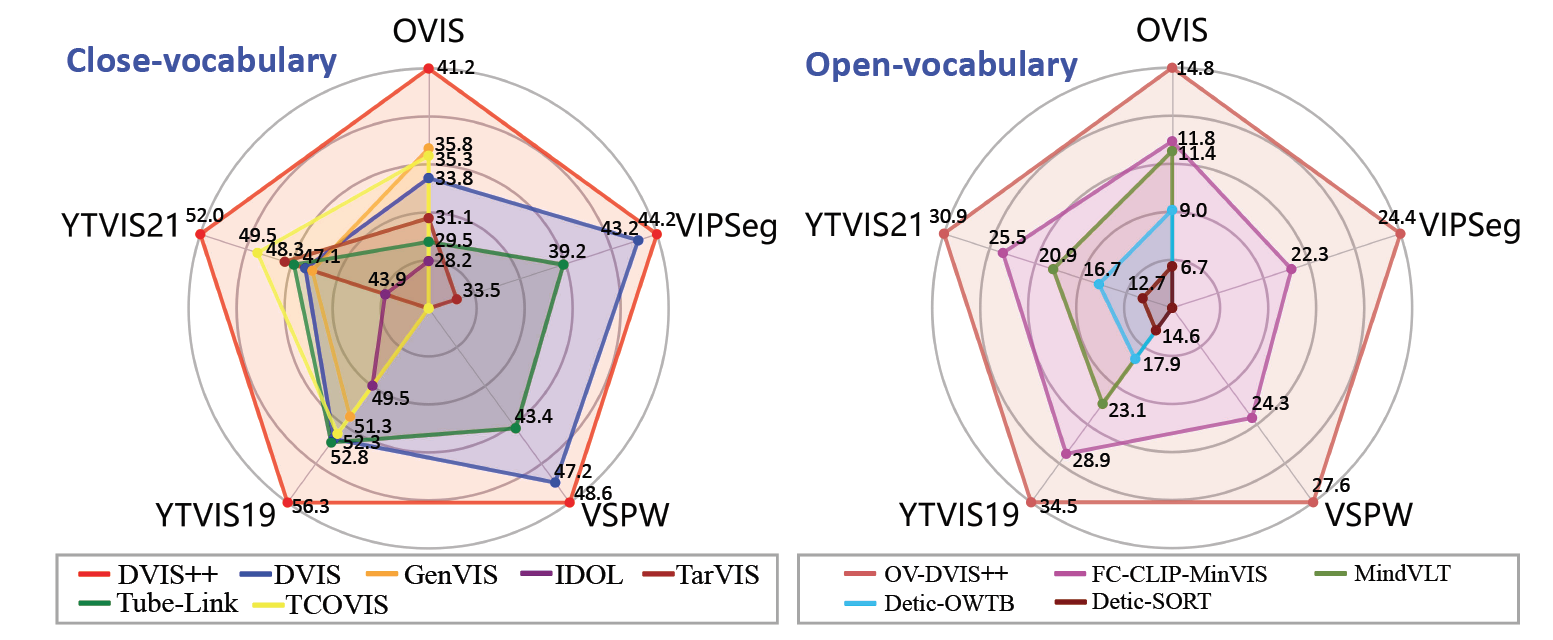
论文在包括语义分割、实例分割和全景分割在内的六个主流基准测试集(YouTube-VIS 2019/2021/2022,OVIS,VSPW,VIPSeg)上开展广泛实验。实验表明,采用统一架构的DVIS++在封闭与开放词汇场景下,其性能均显著超越当前最先进的语义分割、实例分割或全景分割专用方法。
下图展示了OV-DVIS++的开放词汇的分割能力。OV-DVIS++仅在COCO数据集和视频数据集上联合训练。在推理过程中,我们添加了该数据集中从未出现过的新词汇,比如“胡萝卜”、“干草”、“灯笼”、“袋鼠”、“鹅”等。对这些新的目标,OV-DVIS++均能正确分割,展示了强大的可扩展能力。

代码发布于https://github.com/zhang-tao-whu/DVIS_Plus。