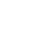近日,学院多项“遥感+AI”研究成果相继被计算机视觉顶级会议CVPR录用。张永军教授“地像天图”课题组2018级博士生魏东及其合作者论文“ELSR: Efficient Line Segment Reconstruction with Planes and Points Guidance”、陈震中教授智能信息处理课题组博士生欧阳君及硕士生米黎合作论文“Object-Relation Reasoning Graph for Action Recognition”、课题组博士生胡姚姒与微软亚洲研究院智能多媒体组合作论文“Make It Move: Controllable Image-to-Video Generation with Text Descriptions”、季顺平教授摄影测量与计算机视觉团队(GPCV)2020级硕士研究生张韬及合作者论文“E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation“等4篇论文被国际计算机视觉与模式识别领域顶级会议CVPR (CCF A类会议)录用。
论文“ELSR: Efficient Line Segment Reconstruction with Planes and Points Guidance”面向大场景三维线云重建存在的精度不高与效率较低的两个难题,创新地提出平面场景稳健探测理论与线段匹配高速响应方法。相比已有算法,两视线云重建精度提高近10%,速度快1000倍。多视线云重建在仅使用CPU情况下,运行速度相比GPU加速的SOTA算法提升近4倍,获取高精度三维线云数量增长近5倍。该成果对于发展高效的点线混合摄影测量新范式具有重要价值。
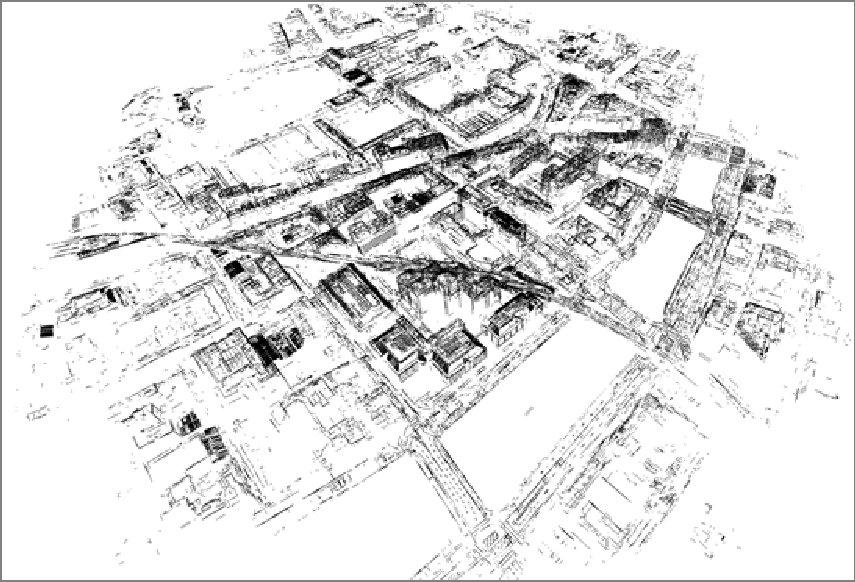

图1:从368张高分辨率航空影像中重建的三维线云,耗时仅9分钟
论文“Object-Relation Reasoning Graph for Action Recognition” 提出目标关系推理图卷积网络(OR2G),从可解释性角度对动作进行推理,通过将动作分解为一系列时序的目标和关系,构建目标级别图和关系级别图分别对时序目标和关系进行推理。在Action Genome数据集上,相比于传统方法获得了较大性能提升,促进动作识别任务向基于语义推理的方向发展。
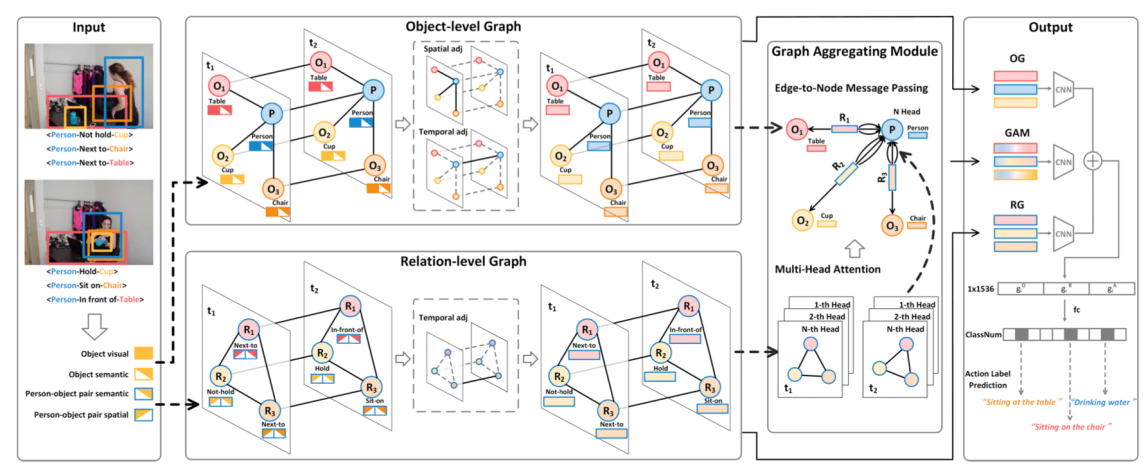
图2: 目标关系推理图卷积网络OR2G
论文“Make It Move: Controllable Image-to-Video Generation with Text Descriptions”针对视频生成这一计算机视觉领域极具挑战性课题,提出了一种新颖的文本图像驱动视频生成任务(Text-Image-to-Video generation,TI2V)和基于运动锚点的视频自回归生成模型。通过运动锚实现图像与文本的语义对齐,并以时空对齐方式驱动视频生成。该模型通过引入显式条件以及隐式随机噪声,分别实现对视频速度控制以及模糊文本的多样化视频生成,推动了可控视频生成领域的发展。
图3: 基于运动锚点的视频生成模型MAGE
论文“E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation“采用更接近人类理解的方式,提出一种全新的端到端实时矢量边缘提取(E2EC)方法,在降低边缘提取任务难度的同时极大提升了分割质量。E2EC在所有主流数据集COCO、SBD、KINS和Cityscapes上都取得了最好的性能。在SBD数据集上,相比于最新的SOTA算法Deep Snake,E2EC的mask AP精度高8.8%、boundary AP精度高76.8%,速度快11.4%。据悉,E2EC代码已开源,可便捷地嵌入其他方法,有望成为边缘实例分割的新基准,可广泛应用于自动驾驶、遥感制图、城市规划等。
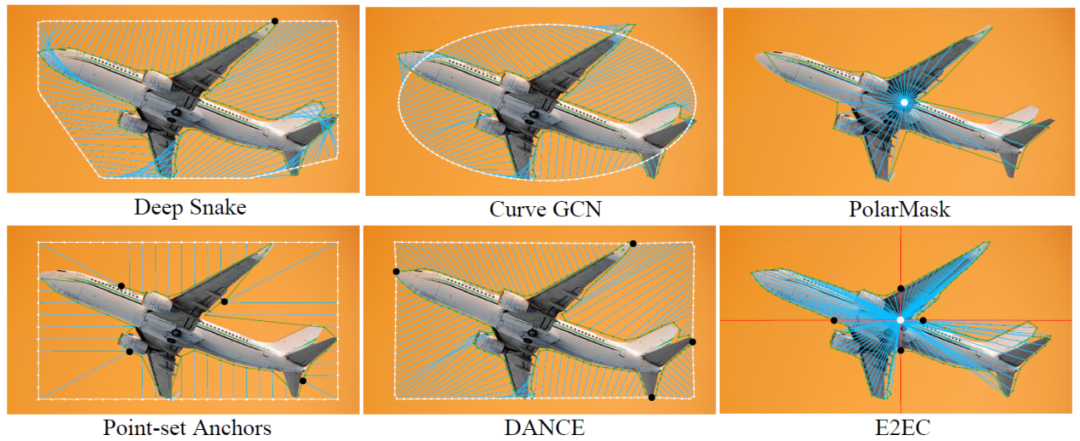

图4: 端到端矢量边缘提取(E2EC)方法
据悉,国际计算机视觉与模式识别大会(IEEE/CVF Conference on Computer Vision and Pattern Recognition,,简称CVPR)是由IEEE主办的计算机视觉、模式识别及人工智能等领域最具影响力和最重要的国际顶级会议,为计算机视觉和人工智能领域公认的世界三大顶级会议之一。