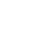近日,我院陈震中教授课题组视频生成论文“LaMD: Latent Motion Diffusion for Image-Conditional Video Generation”(Y. Hu, Z. Chen*, C. Luo)被人工智能顶级期刊《International Journal of Computer Vision》录用(JCR一区,CCF A类期刊,影响因子:14.5)。
AIGC是当前人工智能领域的研究热点,其中视频生成正受到广泛关注,其目标在于生成高质量、流畅自然、且符合用户意图的视频。尽管 AIGC 技术得到了快速发展,但视频生成距离这一目标仍然有一段距离。近年来随着扩散模型的引入,生成视频的画面质量得到了显著提高,但在采样效率以及生成连贯自然的动作方面仍然面临巨大的挑战。针对目前像素空间生成及隐空间图像空间生成两种生成范式在生成效率和运动表征上的局限性,本工作提出一种隐空间运动生成的生成范式,将视频中的内容信息和运动信息进行分解,使得生成模型专注于运动的生成,以提高模型对运动的表征能力并显著降低模型复杂度。
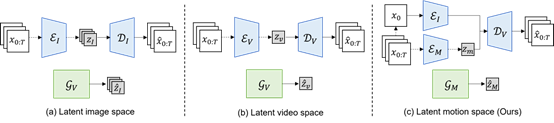
图 1视频生成范式示意图
为实现在该范式下的视频生成,本工作提出了基于隐空间运动分解的视频生成框架,该框架由基于运动分解的视频重建和基于扩散模型的隐空间运动生成两个部分组成。在视频重建中,本工作设计了一个运动-内容分解的视频自编码器,将视频中的运动信息压缩为紧凑的隐空间表征,实现运动的分解以及视频重建。隐空间运动生成则借助扩散模型优越的生成能力,能够在多模态条件下在连续的隐层空间上高效地生成逼真的运动。实验表明本工作提出的模型在多个视频生成任务上取得了优异性能,同时在计算复杂度及生成速度上与图像扩散生成模型相当,极大地减少了资源消耗并大幅提升了采样速度。
我院胡姚姒博士为第一作者,陈震中教授为通讯作者,合作者包括微软亚洲研究院罗翀首席研究员。本研究受到国家自然科学基金人工智能领域(F06)重点项目资助。我院陈震中教授曾为微软学者,其团队与微软亚洲研究院近期在视频生成方向展开合作,在IJCV, CVPR等CCF A类会议或SCI一区期刊上已连续发表多篇论文,并通过微软明日之星项目合作培养多名硕士博士研究生。
图 2 基于隐空间运动分解的视频生成框架

图 3 不同条件下(Happiness vs. Surprise)生成的视频